
Using a database in Individual Investigations
Wednesday 30 August 2017
 It's hard to persuade students that it might be a good ideas to use a database for their investigation. Stuents have lots of experience of manipulating glassware in the lab, but not so much experience at manipulating giant data sets in Excel or another spreadsheet program.
It's hard to persuade students that it might be a good ideas to use a database for their investigation. Stuents have lots of experience of manipulating glassware in the lab, but not so much experience at manipulating giant data sets in Excel or another spreadsheet program.
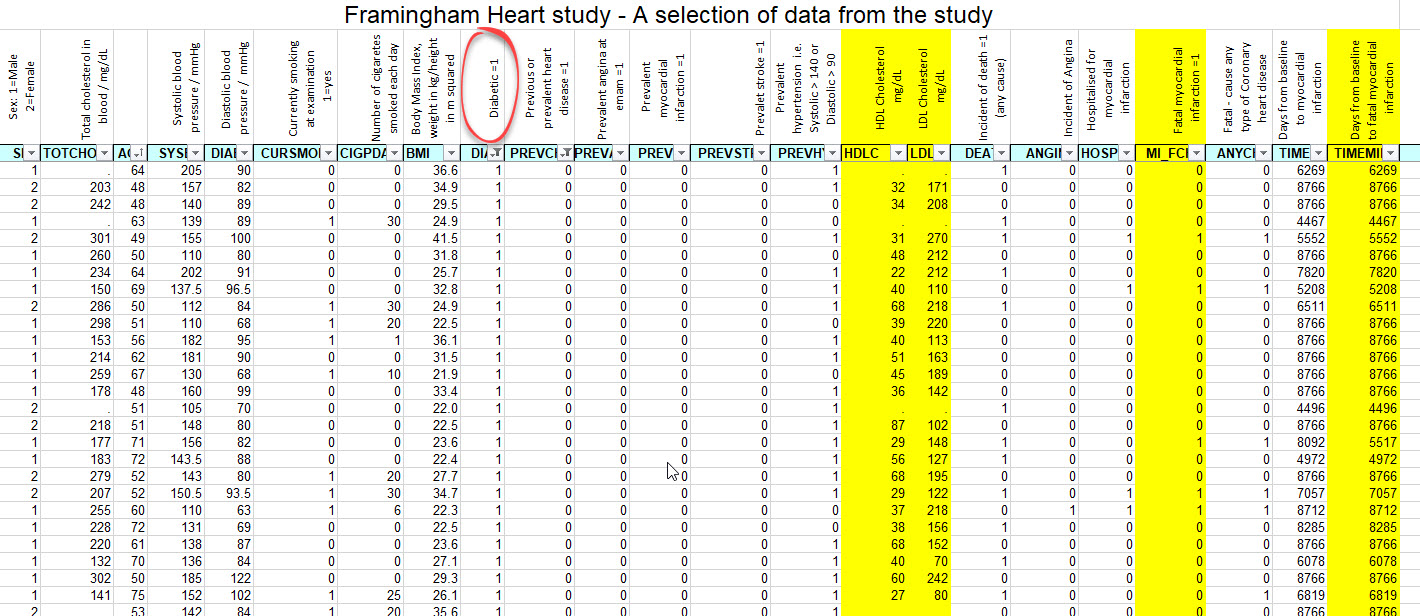
Here are a few ideas of data sets which may be good sources of data. They need to be sufficently complex that students can show how they have selected their data and controled other variables. The activity 3 in the Epidemiology - Framingham heart study page of the Inthinknig biolgoy site provides a short practice activity which incorporates a chi-squared test into a simple analysis of data from a giant cohort study.
NHLBI Teaching Datasets
The NHLBI has prepared three datasets suitable for use in an undergraduate or graduate level biostatistics instruction program. These datasets can be requested at no charge. Request a teaching dataset.
- A longitudinal, epidemiology focused datasets was developed using the Framingham Heart Study as the source for the data. This dataset contains three clinic examination and 20 year follow-up data on a large subset of the original Framingham cohort participants. The documentation for the Framingham dataset contains a variable list and coding help for the data.
- A clinical trial focused dataset was developed using the Digitalis Investigation Group (DIG). This dataset was designed to replicate the results found in the February 1997 NEJM article. The documentation for the DIG dataset contains a variable list and annotated forms.
- A dataset focused on longitudinal, repeated measures was developed using the Childhood Asthma Management Program (CAMP). This dataset includes 695 participants from the CAMP trial and an average of 14 spirometry measures per participant. The documentation includes a variable list, summary tables, and selected annotated form elements.
Public Use Datasets
Public use datasets are anonymized, freely available datasets for research purposes. Since the data is in the public domain, this data can be used by students. Due to the public investment to collect and provide the data, contact information and project titles are requested for the purpose of tracking publications.
National Longitudinal Mortality Study (NLMS)
-
Other epidemiological studies
Busselton Health Study has been carried out since 1966 in a high proportion of the residents of Busselton, a town in Western Australia, over a period of many years.[25] A database has been compiled and is managed by the School of Population Health at the University of Western Australia. Although the results of the Busselton Health Study and the Framingham Heart Study are similar in many aspects, the Busselton Health Study investigated also the influence of some factors that had not been not investigated in the Framingham Heart Study, e.g., sleep apnea.[26][27]
The Caerphilly Heart Disease Study, also known as the Caerphilly Prospective Study (CaPS), is an epidemiological prospective cohort, set up in 1979 in a representative population sample drawn from a typical small town in South Wales, UK.[28] The study has collected wide ranging data and has led to over 400 publications in the medical press, notably on vascular disease, cognitive function and healthy living.[29][30]
China-Cornell-Oxford Project, also known as "China-Oxford-Cornell Study on dietary, lifestyle and disease mortality characteristics in 65 rural Chinese counties". This study was later referred to as "China Study I". The successor study is named "China Study II".[31]